



Table of contents
- The Sheer Scale of GPT-4
- Harnessing the Mixture of Experts
- Training on a Grand Scale
- **
- Taking Advantage of Batch Size
- Innovations in Parallelism
- The Staggering Cost of Training GPT-4
- The Mixture of Experts Tradeoffs
- The Parameters of Power: Understanding GPT-4's Size
- The Data Deluge: GPT-4’s Training Data
- The Computational Conundrum: Parallelism and Batch Sizes
- The Price Tag: GPT-4’s Training Cost
- Mixture of Expert Tradeoffs
- The Final Verdict: Decoding GPT-4
As the world of artificial intelligence continues to evolve, so too do the models that drive it. Recently, OpenAI announced the release of GPT-4, a language model that has not only surpassed its predecessor, GPT-3, in size but also in capabilities. This comprehensive article explores GPT-4 in all its intricate detail, including the features that set it apart, how it functions, and what implications it may have on the future of AI.The Future of AI: Decoding the GPT-4
The Sheer Scale of GPT-4
GPT-4, with its 1.8 trillion parameters, makes its predecessor GPT-3, look like a featherweight. This astounding parameter count, distributed across 120 layers, is more than ten times that of GPT-3. A model’s parameter count is often a good indicator of its ability to learn complex patterns, and the leap in parameter count from GPT-3 to GPT-4 hints at the potential prowess of this latest model. Each parameter represents a piece of information that the model has learned from its training data, contributing to its ability to generate sophisticated and nuanced responses.
Harnessing the Mixture of Experts
One of the keys to managing the complexity and computational demands of such a large model is the Mixture of Experts (MoE) approach. OpenAI's implementation of GPT-4 employs 16 distinct experts, each housing approximately 111 billion parameters. An expert, in this context, is a subset of the model that has specialized knowledge on a specific aspect of the data. The genius of the MoE approach lies in its efficiency. Each forward pass of the model routes through only two of the 16 experts, providing a balance between comprehensive coverage of the parameter space and computational feasibility.
Despite the complexity of GPT-4, the model's routing algorithm is deceptively simple. As it processes inputs, it routes each token to the most appropriate expert, optimizing both the model's understanding of the input and its computational efficiency.
Training on a Grand Scale
GPT-4's scale is not only evident in its size but also in the size of the data it was trained on. The model was trained on a staggering 13 trillion tokens. To put this into perspective, if each token was a word, this would equate to around 260 times the total number of words ever written in human history! However, it's important to note that this figure does not represent unique tokens. The training process involved multiple epochs - two epochs for text data and four epochs for code data. Each epoch represents a complete pass through the dataset, so each token would have been seen multiple times by the model.
Additionally, OpenAI augmented the primary dataset with a significant amount of instruction fine-tuning data, sourced both from ScaleAI and internal sources. Instruction fine-tuning involves providing explicit instructions to the model during the training process, encouraging it to learn specific patterns or behaviors.
**
From 8k to 32k: Fine-Tuning for Success**
The initial pre-training phase for GPT-4 utilized an 8k context length, also known as sequence length (seqlen). This denotes the number of tokens the model considers at a given time. However, a significant development occurred during the fine-tuning phase. A larger 32k seqlen version of GPT-4 emerged, expanding its capacity to consider more extensive context in generating responses. This version was created by fine-tuning the 8k seqlen version after the initial pre-training, allowing GPT-4 to retain more information about previous inputs and make more contextual sense of new ones.
Taking Advantage of Batch Size
In machine learning, the batch size is a significant factor in determining how effectively a model can learn. Larger batches can lead to more stable and reliable gradient updates, while smaller batches can sometimes lead to faster convergence. For GPT-4, the batch size was gradually ramped up over several days until it reached a whopping 60 million tokens.
However, due to the MoE implementation where not every expert sees all tokens, this effectively becomes a batch size of around 7.5 million tokens per expert. In terms of real batch size, this number needs to be divided by the sequence length. This practice points out a prevalent trend in AI - reporting inflated figures can be misleading, so it's always worth diving into the details.
Innovations in Parallelism
One of the major challenges with training such large models is managing computational resources effectively. To address this, OpenAI leveraged several parallelism strategies. The training process was parallelized across an extensive network of A100 GPUs using 8-way tensor parallelism. Beyond this, they employed 15-way pipeline parallelism.
Tensor parallelism involves distributing the computations for a single batch across multiple GPUs. In contrast, pipeline parallelism involves distributing computations for different batches across multiple GPUs. In combination, these techniques allow for efficient training of models that are larger than the memory of a single GPU. It's also likely that OpenAI used Zero Redundancy Optimizer (ZeRo) Stage 1 and block-level Fully Sharded Data Parallelism (FSDP) to optimize memory usage.
The Staggering Cost of Training GPT-4
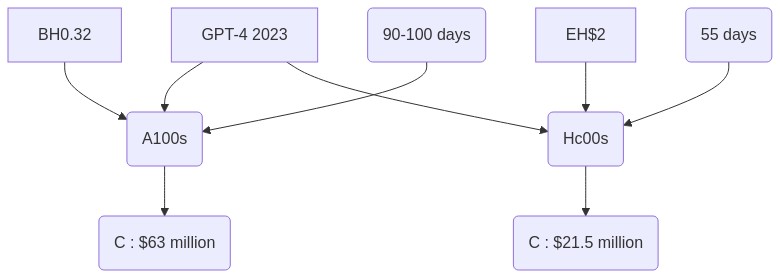
Training large models like GPT-4 comes with a significant financial cost. For instance, the training FLOPs for GPT-4 were estimated to be around ~2.15e25. This training happened on approximately 25,000 A100s over 90 to 100 days, with an estimated utilization of 32% to 36% Maximum Theoretical Utilization (MFU). This lower utilization was largely due to a significant number of failures that required checkpoints and restarts, leading to additional costs.
Based on an estimated cloud cost of $1 per A100 hour, the total training cost for GPT-4 would be around $63 million. Today, this pre-training could be performed with approximately 8,192 H100 GPUs in about 55 days, costing around $21.5 million at a rate of $2 per H100 hour.
The Mixture of Experts Tradeoffs
One of the defining characteristics of GPT-4 is its use of a Mixture of Experts (MoE) model. This architecture includes several unique "experts," each trained to specialize in different aspects of the data. However, using an MoE model introduces specific tradeoffs.
While the MoE approach offers efficiency and scalability benefits, it can be challenging during inference. Because not every part of the model is used for each token generation, some parts may lie dormant when others are in use. This imbalance can hurt utilization rates and increase costs when serving users.
Researchers have suggested that using 64 to 128 experts might achieve better loss than 16 experts, but that's theoretical. In practice, having more experts can make it harder to generalize across different tasks, and it can be more difficult to achieve convergence. Because of these challenges, OpenAI opted for a more conservative approach, using just 16 experts for GPT-4.
The Parameters of Power: Understanding GPT-4's Size
GPT-4 is over ten times larger than GPT-3, with around 1.8 trillion parameters across 120 layers. A parameter in an AI model is a configuration variable that is internal to the model and whose value can be estimated from the training data. They are fundamental to the training of AI models, and the increase in their number contributes to the learning capacity of the model.
In terms of specifics, the GPT-4 model employs a technique called Mixture of Experts (MoE). An MoE model is a machine learning technique that trains multiple "expert" models, each specializing in a different part of the input space. In the case of GPT-4, it utilizes 16 experts, each with about 111 billion parameters for Multilayer Perceptron (MLP), a class of feedforward artificial neural network. Interestingly, not all experts are active per forward pass – only two are routed to.
This innovative use of MoE allows for a more efficient use of computational resources. As a result, each forward pass (generation of 1 token) only uses about 280 billion parameters and 560 TeraFLOPs (trillion Floating-Point Operations Per Second), a stark contrast to the approximately 1.8 trillion parameters and 3,700 TFLOP that would be required per forward pass of a densely populated model.

The Data Deluge: GPT-4’s Training Data
GPT-4 was trained on an estimated 13 trillion tokens. Tokens, in this context, refer to the smallest units of data that the AI model can learn from. Notably, these are not unique tokens – they also count the epochs as more tokens. An epoch is one complete pass through the entire training dataset.
The model underwent 2 epochs for text-based data and 4 epochs for code-based data. Furthermore, the model was fine-tuned with millions of rows of instruction data provided by ScaleAI and OpenAI's internal data.
Additionally, the model has versions based on context length, or sequence length (seqlen), that indicate the maximum length of sequence the model can take as input. GPT-4 was pre-trained with an 8k sequence length, while the 32k sequence length version is based on fine-tuning of the 8k after the pre-training.
The Computational Conundrum: Parallelism and Batch Sizes
In the AI world, parallelism and batch sizes are critical components. Parallelism helps in splitting the task into subtasks and running them simultaneously, thereby saving time. Batch size, on the other hand, refers to the number of training examples utilized in one iteration.
OpenAI utilized 8-way tensor parallelism, the limit for NVLink, a high-bandwidth interconnect developed by NVIDIA. Beyond that, they implemented 15-way pipeline parallelism.
During training, the batch size was gradually ramped up over a number of days on the cluster. By the end of this period, OpenAI was using a whopping batch size of 60 million. However, due to not every expert seeing all tokens, the effective batch size per expert was around 7.5 million tokens.
The real batch size is calculated by dividing this number by the sequence length, which gives a more accurate representation of the data being processed at once.
The Price Tag: GPT-4’s Training Cost
Training AI models of this magnitude is a costly affair. OpenAI’s training FLOPS (Floating Point Operations Per Second, a measure of computer performance) for GPT-4 is estimated to be around 2.15e25, run on approximately 25,000 A100s (a high-performance NVIDIA graphics processing unit) for 90 to 100 days at about 32% to 36% Maximum Fabric Utilization (MFU).
This lower utilization rate was a result of a large number of failures that required checkpoints to be restarted. If calculated with a cost in the cloud of about $1 per A100 hour, the training costs for this run alone would be about $63 million. Today, however, pre-training could be done with approximately 8,192 H100 GPUs in around 55 days for $21.5 million at $2 per H100 hour.
Mixture of Expert Tradeoffs
As with any model, tradeoffs are a necessity. For instance, MoE models, although efficient, are notoriously challenging to deal with during inference because not every part of the model is utilized on every token generation. This results in some parts remaining dormant when others are being used, significantly affecting utilization rates when serving users.
Research has indicated that using 64 to 128 experts achieves a better loss (a measure of how well the model has learned) to FLOPs ratio, but at the cost of potentially worse utilization. To improve this, OpenAI used a load balancing algorithm which ensured that the use of experts was more or less equal across the tokens.
The Final Verdict: Decoding GPT-4
All in all, GPT-4 is a major achievement in the AI world. It is a testament to the continued growth and evolution of artificial intelligence, and the increasing capability of machines to understand and generate human-like text. As technology continues to advance, we can only expect that models like GPT-4 will become even more sophisticated and capable.
There is, of course, the question of ethics and the potential for misuse. As AI models become more advanced, the potential for them to be used maliciously increases. It's important for us as a society to have serious discussions about the implications of this technology and to implement safeguards to ensure that it is used responsibly.